# Device Mesh
### What is DeviceMesh ?
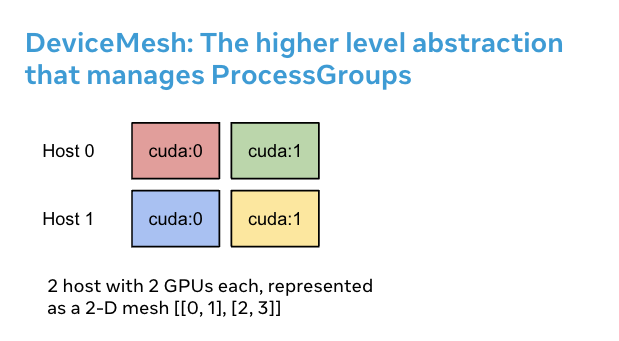
- DeviceMesh is a higher level abstraction that manages ProcessGroup. It allows users to effortlessly create inter-node and intra-node process groups without worrying about how to set up ranks correctly for different sub process groups. Users can also easily manage the underlying process_groups/devices for multi-dimensional parallelism via DeviceMesh.
### Why DeviceMesh is Useful ?
- DeviceMesh is useful when working with multi-dimensional parallelism (i.e. 3-D parallel) where parallelism composability is required. For example, when your parallelism solutions require both communication across hosts and within each host. The image above shows that we can create a 2D mesh that connects the devices within each host, and connects each device with its counterpart on the other hosts in a homogenous setup.
- Without DeviceMesh, users would need to manually set up NCCL communicators, cuda devices on each process before applying any parallelism, which could be quite complicated. With the help of init_device_mesh(), we can accomplish the above 2D setup in just two lines, and we can still access the underlying ProcessGroup if needed.
```python
from torch.distributed.device_mesh import init_device_mesh
mesh_2d = init_device_mesh("cuda", (2, 4), mesh_dim_names=("replicate", "shard"))
# Users can access the underlying process group thru `get_group` API.
replicate_group = mesh_2d.get_group(mesh_dim="replicate")
shard_group = mesh_2d.get_group(mesh_dim="shard")
```
- To run the above code snippet, we can leverage PyTorch Elastic
torchrun --nproc_per_node=8 2d_setup_with_device_mesh.py
### How to use DeviceMesh with HSDP ?
- Hybrid Sharding Data Parallel(HSDP) is 2D strategy to perform FSDP within a host and DDP across hosts. Let’s see an example of how DeviceMesh can assist with applying HSDP to your model with a simple setup. With DeviceMesh, users would not need to manually create and manage shard group and replicate group.
```python
class ToyModel(nn.Module):
def __init__(self):
super(ToyModel, self).__init__()
self.net1 = nn.Linear(10, 10)
self.relu = nn.ReLU()
self.net2 = nn.Linear(10, 5)
def forward(self, x):
return self.net2(self.relu(self.net1(x)))
# HSDP: MeshShape(2, 4)
mesh_2d = init_device_mesh("cuda", (2, 4))
model = FSDP(
ToyModel(), device_mesh=mesh_2d, sharding_strategy=ShardingStrategy.HYBRID_SHARD
)
```
- Then, run the following torch elastic/torchrun command.
torchrun --nproc_per_node=8 hsdp.py