Shopify Merlin¶
Introduction
Context: Shopify’s ML platform team builds infrastructure and tools to streamline ML workflows for data scientists.
Use Cases:
Internal: Fraud detection, revenue predictions.
External (Merchant/Buyer Facing): Product categorization, recommendation systems.
Need for Redesign: Required a platform to handle diverse requirements, inputs, data types, dependencies, and integrations, enabling use of best-of-breed tools.
Focus of Post: Introduction to Merlin, its architecture, user workflow, and a product use case.
The Magic of Merlin
Foundation: Based on an open-source stack.
Objectives:
Scalability: Robust infrastructure for scaling ML workflows.
Fast Iterations: Reduce friction, minimize prototype-to-production gap.
Flexibility: Allow users to use any necessary libraries/packages.
Initial Focus (First Iteration): Training and batch inference.
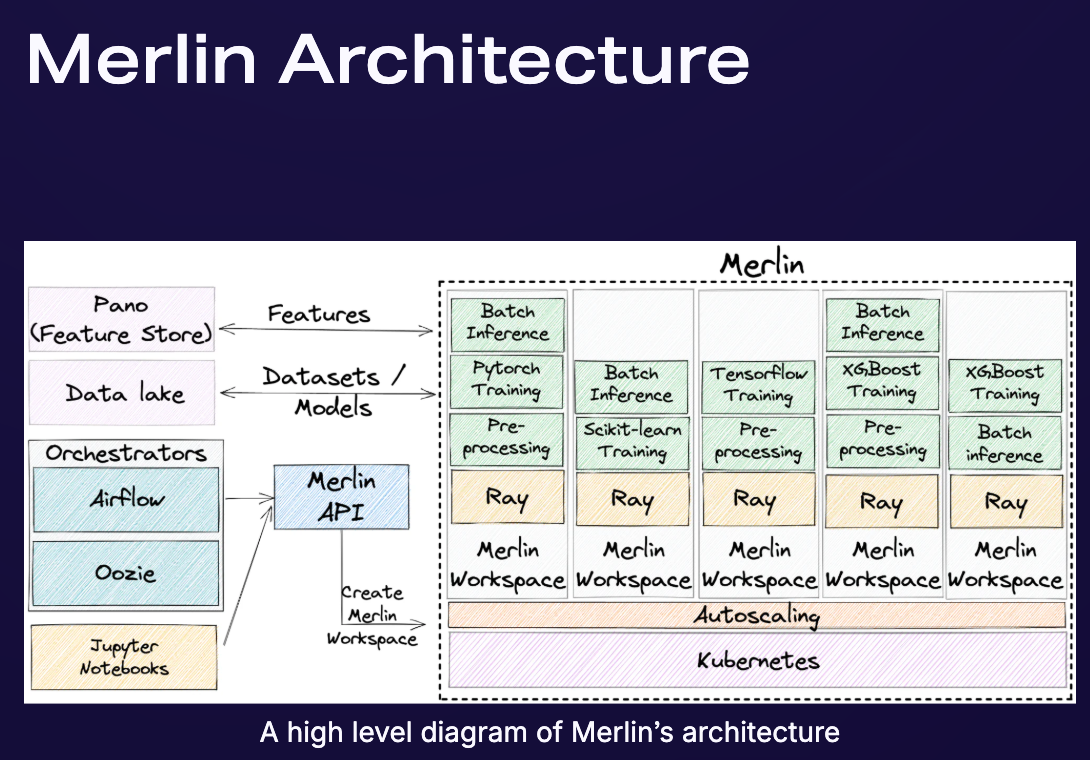
Merlin Architecture
Data Input: Uses features and datasets from Shopify’s data lake or Pano (feature store), typically pre-processed by tools like Spark.
Merlin Workspaces:
Dedicated environments for each use case (tasks, dependencies, resources).
Enable distributed computing and scalability.
Underlying Technology: Short-lived Ray clusters deployed on Shopify’s Kubernetes cluster (for batch jobs).
Merlin API: Consolidated service for on-demand creation of Merlin Workspaces.
User Interaction: Users can interact with Merlin Workspaces from Jupyter Notebooks (prototyping) or orchestrate via Airflow/Oozie (production).
Core Component: Ray.
What Is Ray?
Definition: Open-source framework with a simple, universal API for building distributed systems and tools to parallelize ML workflows.
Ecosystem: Includes distributed versions of scikit-learn, XGBoost, TensorFlow, PyTorch, etc.
Functionality: Provides a cluster to distribute computation across multiple CPUs/machines.
ray.init(): Starts a Ray runtime (local or connects to existing local/remote cluster). Enables seamless code transition from local to distributed.Ray Client API: Used to connect to remote Ray clusters.
Example (XGBoost on Ray):
Uses
xgboost_rayintegration.RayParamsdefine distribution (e.g.,num_actors,cpus_per_actor).RayDMatrixfor distributed data representation.train()function executes distributed training.
Ray In Merlin
Rationale for Choosing Ray:
Python-centric development at Shopify.
Enables end-to-end Python ML workflows.
Integrates with existing ML libraries.
Easily distributes/scales with minimal code changes.
Usage: Each ML project in Merlin includes Ray for distributed preprocessing, training, and prediction.
Prototype to Production: Ray facilitates this by allowing code developed locally/in notebooks to run on remote Ray clusters at scale from early stages.
Adopted Ray Features:
Ray Train: For distributed deep learning (TensorFlow, PyTorch).
Ray Tune: For experiment execution and hyperparameter tuning.
Ray Kubernetes Operator: For managing Ray deployments on Kubernetes and autoscaling Ray clusters.
Building On Merlin (User’s Development Journey)
Creating a new project: User creates a Merlin Project (code, requirements, packages).
Prototyping: User creates a Merlin Workspace (sandbox with Jupyter) for distributed/scalable prototyping.
Moving to Production: User updates Merlin Project with finalized code/requirements.
Automating: User orchestrates/schedules the workflow (via Airflow DAGs) in production.
Iterating: User spins up another Merlin Workspace for new experiments.
Merlin Projects
Purpose: Dedicated to specific ML tasks (training, batch prediction).
Customization: Specify system-level packages or Python libraries.
Technical Implementation: Docker container with a dedicated virtual environment (Conda, pyenv) for code/dependency isolation.
Management: CLI for creating, defining, and using Merlin Projects.
config.yml: Specifies dependencies and ML libraries.srcfolder: Contains use-case-specific code.CI/CD: Pushing code to a branch triggers a custom Docker image build.
Merlin Workspaces
Creation: Via centralized Merlin API (abstracts infrastructure logic like K8s Ray cluster deployment, ingress, service accounts).
Resource Definition: Users can define required resources (GPUs, memory, CPUs, machine types).
Execution Environment: Spins up a Ray cluster in a dedicated Kubernetes namespace using the Merlin Project’s Docker image.
API Payload Example: Specifies
name,min_workers,max_workers,cpu,gpu_count,gpu_type,memory,enable_jupyter,image.Lifecycle: Can be shut down manually or automatically after job completion, returning resources to the K8s cluster.

Prototyping From Jupyter Notebooks
Environment: Users spin up a new ML notebook in Shopify’s centrally hosted JupyterHub environment using their Merlin Project’s Docker image (includes all code/dependencies).
Remote Connection: Use Ray Client API from the notebook to connect remotely to their Merlin Workspaces.
Distributed Computation: Run remote Ray Tasks and Ray Actors to parallelize work on the underlying Ray cluster.
Benefit: Minimizes prototype-to-production gap by providing full Merlin/Ray capabilities early.
Moving to Production
Code Update: Push prototyped code to Merlin Project, triggering a new Docker image build via CI/CD.
Orchestration:
Build ML flows using declarative YAML templates or configure Airflow DAGs.
Jobs scheduled periodically, call Merlin API to spin up Workspaces and run jobs.
Monitoring & Observability:
Datadog: Dedicated dashboard per Merlin Workspace for job monitoring and resource usage analysis.
Splunk: Logs from each Merlin job for debugging.
Onboarding Shopify’s Product Categorization Model to Merlin
Use Case Complexity: Requires several workflows for training and batch prediction; chosen to validate Merlin due to large-scale computation and complex logic.
Migration: Training and batch prediction workflows migrated to Merlin and converted using Ray.
Migrating the training code:
Integrated TensorFlow training code with Ray Train.
Minimal code changes: original TF logic mostly unchanged, encapsulated in a
train_func.Trainerobject fromray.trainconfigured with backend (“tensorflow”),num_workers,use_gpu.trainer.run(train_func, config=config)executes distributed training.
Migrating inference:
Multi-step process, each step migrated separately.
Used Ray ActorPool to distribute batch inference steps. (Similar to Python’s
multiprocessing.Pool).Predictorclass (Ray Actor): Contains logic for loading model and performing predictions.Actors created based on available cluster resources (
ray.available_resources()["CPU"]).ActorPool.map_unordered()used to send dataset partitions to actors for prediction.Future Improvement: Plan to migrate to Ray Dataset Pipelines for more robust data load distribution and batch inference.
What’s next for Merlin
Aspiration: Centralized platform streamlining ML workflows, enabling data scientist innovation.
Next Milestones:
Migration: Migrate all Shopify ML use cases to Merlin; add a low-code framework for new use cases.
Online inference: Support real-time model serving at scale.
Model lifecycle management: Add model registry and experiment tracking.
Monitoring: Support ML-specific monitoring.
Current Status: New platform, already providing scalability, fast iteration, and flexibility.